How To Separate PDF Pages: Precise Methods for Perfect Page Extraction
How To Separate PDF Pages: Precise Methods for Perfect Page Extraction
Unlocking the contents of a compacted PDF often requires isolating individual pages—whether for printing, editing, archiving, or legal review. Separating PDF pages is a common need across personal and professional contexts, yet the process demands attention to detail and the right tools. While file compression formats promise convenience, real-world scenarios—such as overcrowded digital documents, scanned booklets, or merged report folders—frequently call for reliable page separation.
This guide reveals the proven techniques, tools, and best practices to extract PDF pages with precision and efficiency, transforming tangled documents into clean, usable parts.
The Challenge of PDF Page Isolation
PDFs are not inherently paginated interfaces; each page is embedded within a single file structure, making extraction non-trivial. Files may contain pictures, hidden layers, or layouts that defy simple extraction.Many PDFs originate from scanning paper documents, resulting in pages flattened into a single image stream—especially problematic for text-based or annotated content. According to digital workflow experts, “Accurate page separation hinges not just on software capability, but on understanding how payloads are compressed and laid out internally,” underscoring the technical nuance behind even basic extraction tasks. Moreover, ensuring text integrity, maintaining proper order, and preserving formatting are critical for professional use—text misalignment or data loss can derail legal, academic, and administrative workflows.
Improper handling risks rendering extracted pages illegible or unusable, emphasizing the need for reliable, tested methods.
Top Methods to Separate PDF Pages
Several effective approaches exist, each with distinct advantages based on file origin, size, and intended outcome.Using Built-in Document Editors
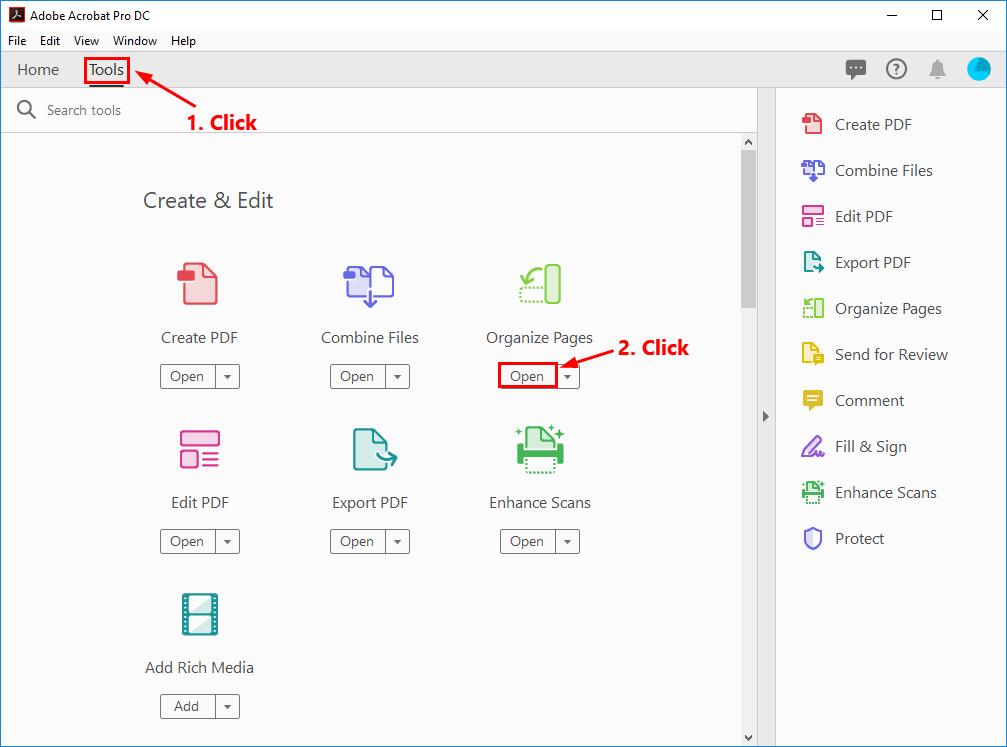
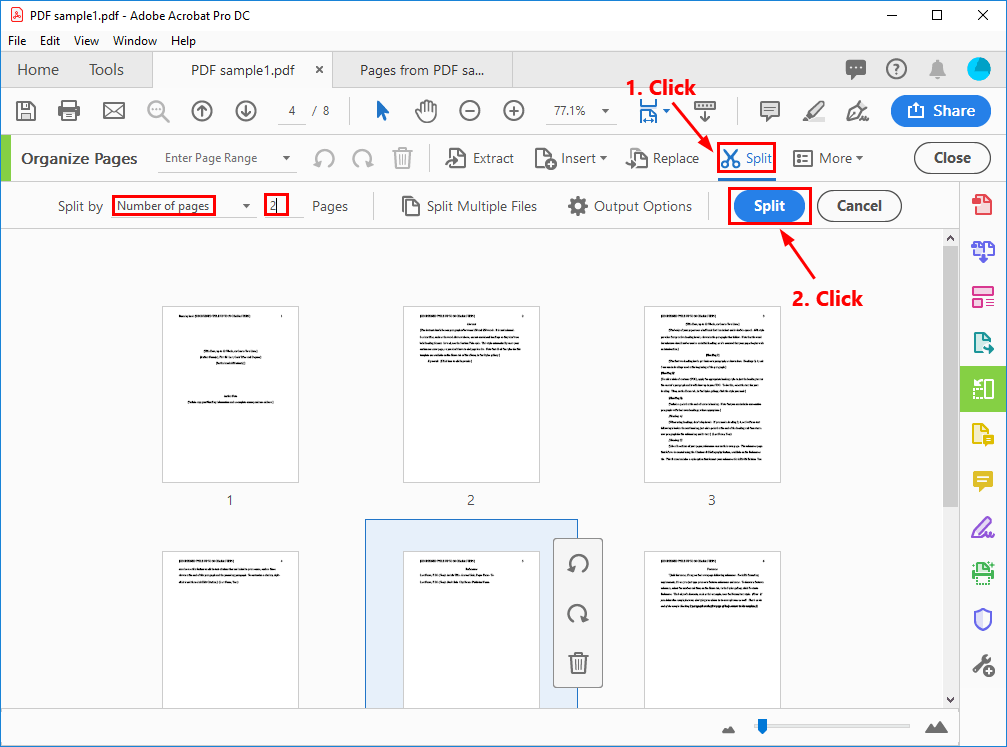
Popular software like Adobe Acrobat, Microsoft Print to PDF, and Corel WordPerfect Reader include page extraction features designed for quick access.Adobe Acrobat, a standard in professional environments, offers a direct page selector—and with version 9.0 and later, supports separating multi-page files into standalone documents. “Adobe continues to streamline core functions, allowing users to extract pages with minimal clicks while preserving layout fidelity,” notes a product specialist. These tools excel for routine use, especially with native or scanned PDFs under moderate size.
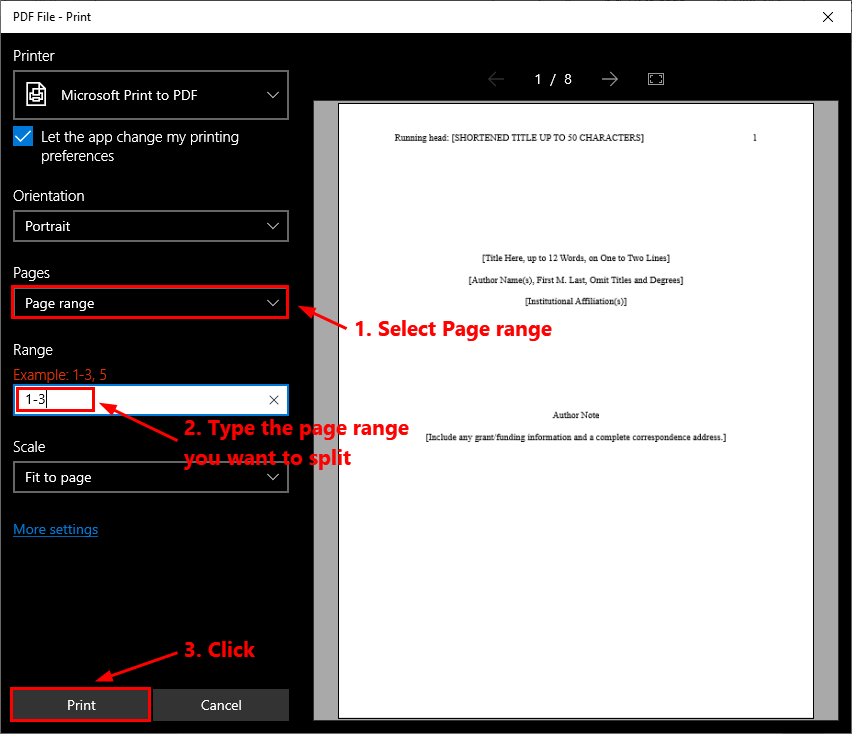
For common users, built-in print functions often deliver surprising reliability: selecting “Print” → “Save as PDF” with “Single Page” orientation ensures one-page documents are saved cleanly—ideal for straightforward separation without third-party software.
Dedicated PDF Manipulation Tools
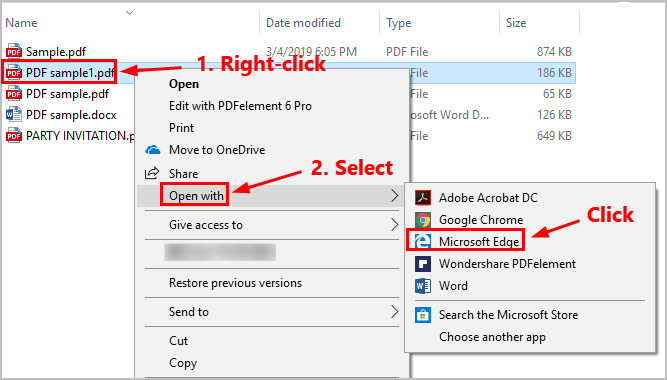
For advanced control, specialized PDF editors such as PDFsam Basic, PDFelement, or Sejda PDF Editor deliver robust separation capabilities. These tools support batch processing, enabling extraction of entire file sets or individual pages across thousands of documents.Features include pagination algorithms that intelligently detect margins, headers, footers, and multi-column layouts—critical for scanned documents with complex formatting. “PDF manipulation tools are indispensable when working with diverse PDF structures,” explains a forensic document specialist. “They parse not just content, but spatial data, ensuring extracted pages retain original positioning and hierarchy—essential for legal and archival applications.” Using batch modes or drag-and-drop interfaces, users extract pages safely, reducing human error and saving hours on repetitive tasks.
Online and Cloud-Based Solutions
Cloud services like Smallpdf, PDF Coffee, and ILovePDF offer accessible alternatives with no installation required. These platforms support free page extraction with intuitive uploads and page selection via browser. Ideal for casual users or one-off tasks, they often include OCR (Optical Character Recognition) for scanned pages, converting images to text before separation.However, handling sensitive documents online introduces privacy concerns. Reputable platforms mitigate risk through encryption and deletion policies, but digitally savvy users should weigh data sensitivity against convenience. As one IT security consultant warns, “Suppose confidentiality is key—local tools remain safer, though online options grow safer with end-to-end encryption standards.”
Scripting and Automation for Power Users
For those comfortable with scripting, automated extraction via command-line tools offers unmatched precision.Opera PDF Library, PyPDF2 (Python), or Adobe’s PDF tools via scripting enable batch processing, layout analysis, and metadata handling. A typical Python script using PyPDF2 reads each page, extracts content, and saves separate files with clear naming—perfect for integrating into larger document workflows. “Scripting transforms page separation from a manual chore into an automated, repeatable process,” notes a software engineer.
“It’s ideal for enterprise systems where consistency and speed are paramount.”
Step-by-Step Guide to Safe and Effective Page Extraction
To separate PDF pages efficiently and accurately: 1. **Assess Document Type**: Determine if pages are image-based (scanned) or text-based (digitally created). Scanned files typically require OCR; text-based PDFs work best with direct extraction.2. **Choose the Right Tool**: For casual use, built-in editors or small online tools suffice. Professional settings demand robust software like Adobe or PDFelement.
Scripting suits automation needs. 3. **Prepare the Document**: Confirm the PDF is complete and correctly formatted; repair corrupted files if necessary using repair tools.
4. **Extract Pages Strategically**: - Open the document using your chosen software. - Select “Extract Pages” or “Page Separator” function.
- For multi-page PDFs, choose one page at a time or batch extract using drag-and-drop. - For scanned documents, enable OCR post-extraction. 5.
**Validate Output**: Manually verify a sample extracted page. Check layout, readability, and order—aspiring clarity prevents downstream issues. 6.
**Secure Sensitive Files**: When handling confidential documents, use encrypted tools, enable local processing, and delete temporary files post-use.
Best Practices for Maintaining Page Integrity
- Always extract at high DPI to preserve clarity, especially for print-ready pages. - When scanning on the fly, flatten pages strictly to avoid duplication or rotation errors.- For OCR in scanned PDF
Related Post

What Does NKT Mean in Text? Unlocking the Hidden Layers of a Modern Digital Abbreviation

Tanqur

Get Free Instagram Followers: A Trial Guide to Safe, Sustainable Growth

Ragdoll Hit GitLab: Revolutionizing CI/CD with Advanced Integration and Deployment Power



